
1. 왜 API를 전환했는가 - 12초짜리 API
현재 개발 중인 프로젝트는 N명의 참여자가 모두 공평하게 이동할 수 있는 최적의 만남 장소를 찾는 서비스입니다.
핵심 알고리즘
1. 참여자 N명의 위치 → 무게중심(centerPoint) 계산
2. 무게중심 5km 반경 내 지하철역 M개 검색
3. 각 역까지 모든 참여자의 대중교통 경로 탐색
4. MinSum(총 이동시간 최소) 기준 Top 3 추천
평가 지표
- minSum: 모든 참여자 이동시간의 합계 (가장 중요)
- minMax: 가장 먼 참여자의 이동시간 (공평성)
- avgDuration: 평균 이동시간
초기 구현: ODsay API 선택 이유
- ✅ 국내 대중교통 특화 (환승 정보 정확도 높음)
- ✅ 무료 API (비용 부담 없음)
- ❌ Rate Limit 엄격 (동시 요청 제한)
- ❌ 배치 호출 미지원 (N×M회 개별 호출 필수)
문제 인식
참여자 6명 × 후보 역 5개 = 30회 API 호출이 필요한 상황에서 ODsay의 Rate Limit으로 인해 순차 호출이 불가피했고
이는 12초라는 끔찍한 응답 시간으로 이어졌습니다.
1.1. 초기 구현: ODsay API 순차 호출
// 초기 구현
public MidpointRecommendationResponse calculateMidpoint(List<ParticipantInfo> participants) {
// 1. 무게중심 계산
CenterPoint center = calculate3DCentroid(participants);
// 2. Kakao API로 근처 지하철역 5개 검색
List<SubwayStation> stations = kakaoClient.searchSubwayStations(center, 5000, 5);
// 3. 각 역에 대해 모든 참여자의 경로 탐색 (순차)
for (SubwayStation station : stations) { // 5개 역
for (ParticipantInfo participant : participants) { // 6명
// ODsay API 개별 호출
OdsayPathInfo pathInfo = odsayClient.searchRoute(...);
Thread.sleep(100); // Rate Limit 보호
}
}
// 4. 정렬 후 Top 3 반환
}
문제점
- API 호출 횟수: 5개 역 × 6명 = 30회
- 1회 소요 시간: 200ms (API) + 100ms (딜레이) = 300ms
- 총 응답 시간: 300ms × 30회 = 9,000ms + 기타 처리 = 약 12초
참여자 6명 × 후보 역 5개 = 30회 API 호출 → 12초 대기
사용자 경험
- "중간 장소 추천해줘" 클릭
- 12초 대기... ⏱️
- "앱 죽은 건가?" 🤔
- 뒤로가기 (이탈)
2. 시도 1: 병렬 처리의 한계
"그럼 병렬로 하면 되지 않을까?"
아이디어: 5개 역의 평가는 서로 독립적이니까 동시에 처리하자!
아래는 병렬 처리로 개선한 이전 글 입니다.
https://hyunolike.tistory.com/36
[프로젝트] N명의 최적 만남 장소 찾기: 지리 알고리즘 설계와 실시간 응답 개선 (feat. CompletableFutu
1. 프로젝트 개요여러 명이 만남을 약속할 때 모두에게 공정한 최적의 만남 장소를 추천하는 API를 만들었습니다. 1.1. 핵심 로직참가자들의 위치를 받아 지리적 중심점 계산 (3D 좌표 변환)중심점
hyunolike.tistory.com
// CompletableFuture로 역 단위 병렬 처리
ExecutorService executor = Executors.newFixedThreadPool(5);
List<CompletableFuture<EvaluatedPlace>> futures = stations.stream()
.map(station -> CompletableFuture.supplyAsync(() -> {
// 이 역에 대한 6명의 경로 순차 조회
for (ParticipantInfo participant : participants) {
odsayClient.searchRoute(...);
Thread.sleep(200); // Rate Limit 보호
}
}, executor))
.toList();
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
기대 효과
- 5개 역을 동시 처리 → 가장 느린 역 하나의 시간 (6명 × 300ms = 1,800ms)
- 12초 → 약 2초 예상
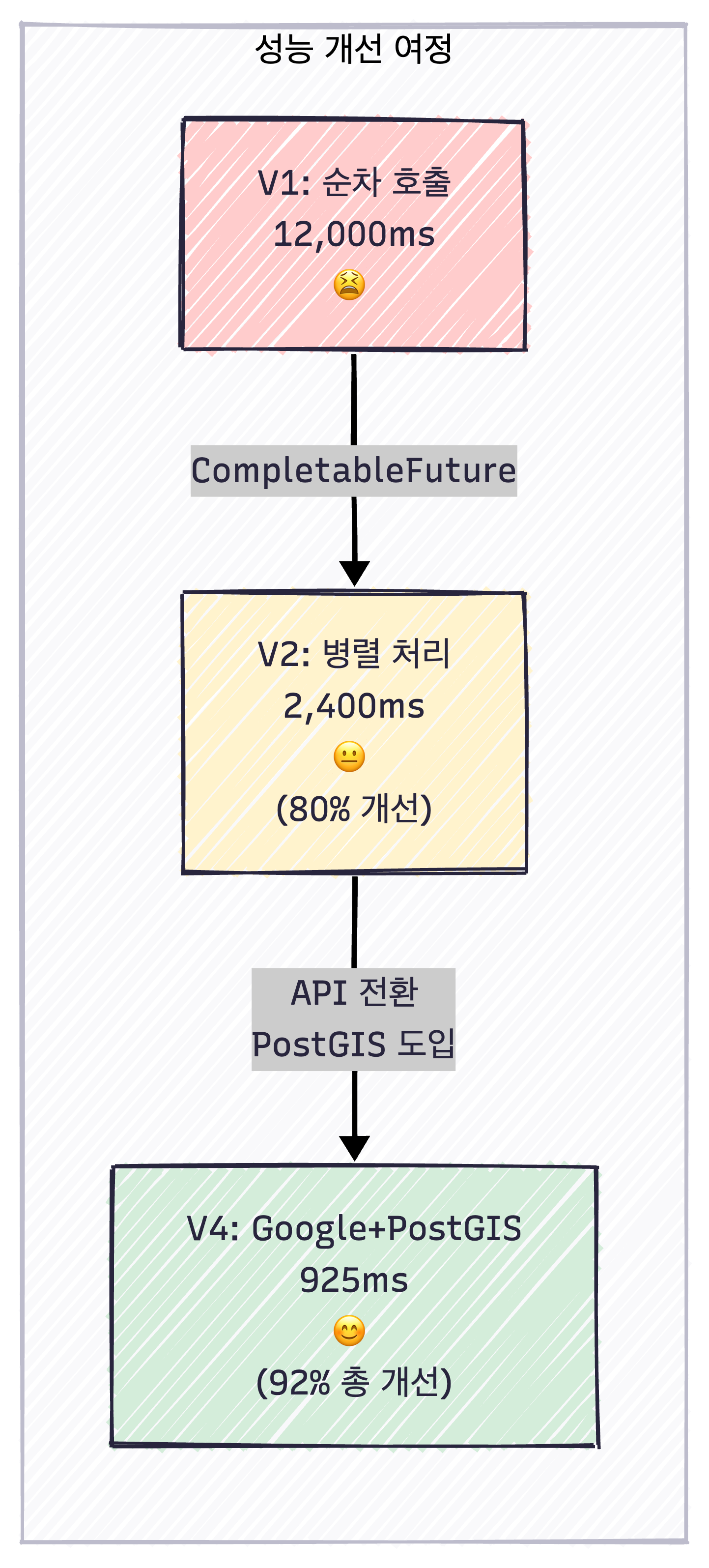
실제 결과: 약 4초 (67% 개선)
왜 병렬 처리가 근본 해결책이 아닌가?
문제 1: Rate Limit 충돌
[스레드1] 역A-참여자1 호출 ━━
[스레드2] 역B-참여자1 호출 ━━ } 동시 5개 호출
[스레드3] 역C-참여자1 호출 ━━ } → 429 Too Many Requests!
[스레드4] 역D-참여자1 호출 ━━
[스레드5] 역E-참여자1 호출 ━━
해결 시도: Semaphore로 동시 요청 제한 + Exponential Backoff 재시도
private final Semaphore rateLimiter = new Semaphore(5);
public OdsayPathInfo searchRoute(...) {
for (int attempt = 0; attempt <= MAX_RETRIES; attempt++) {
rateLimiter.acquire();
try {
String response = odsayRestTemplate.getForObject(url, String.class);
if (response.contains("429")) {
Thread.sleep(500 * (1L << attempt)); // 지수 백오프
continue;
}
return parseResponse(response);
} finally {
rateLimiter.release();
}
}
}
결과: 안정화되었지만 3.4초 (재시도 오버헤드)
문제 2: 여전히 느림
- 목표: 1초 이내
- 현재: 3.4초
- 격차: 180% 초과
핵심 깨달음
"증상을 치료하는 게 아니라 근본 원인을 해결해야 한다"
근본 원인
- ODsay API는 배치 호출을 지원하지 않는다
- → N×M회 개별 호출이 불가피
- → 병렬 처리해도 한계가 명확
필요한 것
- 배치 호출을 지원하는 API
- 외부 API 의존도를 낮추는 방법
3. 근본 해결 1: Google API 배치 호출
Google Distance Matrix API 선택 이유
| 항목 | ODsay API | Google Distance Matrix API |
| 배치 호출 | ❌ 미지원 | ✅ N origins × M destinations 지원 |
| Rate Limit | 초당 5회 (엄격) | 초당 100 elements (여유) |
| 비용 | 무료 | 월 40,000 elements 무료 |
| 안정성 | 중간 | 매우 높음 (글로벌 서비스) |
결정적 차이: Google API는 1회 요청으로 N×M 경로를 조회할 수 있다!
배치 호출 구조
Before: ODsay (30회 개별 호출)
역A ━ 참여자1 [API 호출 1]
역A ━ 참여자2 [API 호출 2]
역A ━ 참여자3 [API 호출 3]
...
역E ━ 참여자6 [API 호출 30]
After: Google (2회 배치 호출)
왜 2회인가?
- Transit 모드 (대중교통 경로) - 1회 배치 호출
- Driving 모드 (자가용 경로) - 1회 배치 호출
- → 사용자에게 대중교통/자가용 두 가지 옵션 제공
# 1회차: 대중교통 경로 (6명 × 10역 = 60개 경로)
GET https://maps.googleapis.com/maps/api/distancematrix/json
?origins=37.5665,126.9780|37.4979,127.0276|37.5407,127.0696|...
&destinations=37.5779,126.8997|37.5572,126.9236|...
&mode=transit ← 대중교통
&key=YOUR_API_KEY
# 2회차: 자가용 경로 (6명 × 10역 = 60개 경로)
GET https://maps.googleapis.com/maps/api/distancematrix/json
?origins=37.5665,126.9780|37.4979,127.0276|37.5407,127.0696|...
&destinations=37.5779,126.8997|37.5572,126.9236|...
&mode=driving ← 자가용
&key=YOUR_API_KEY
GoogleDistanceMatrixResponse transitResponse =
googleDistanceMatrixClient.calculateDistanceMatrix(origins, destinations, "transit");
GoogleDistanceMatrixResponse drivingResponse =
googleDistanceMatrixClient.calculateDistanceMatrix(origins, destinations, "driving");
파라미터
- origins: 6개 참여자 위치 (파이프 | 구분)
- destinations: 10개 후보 역 위치
- 1회 호출 = 6×10 = 60개 경로 정보
- 2회 호출 = 120개 경로 정보 (transit 60개 + driving 60개)
응답 구조 (N×M 행렬)
{
"rows": [
{
"elements": [
{"duration": {"value": 1500}, "distance": {"value": 12000}, "status": "OK"},
{"duration": {"value": 1320}, "distance": {"value": 9500}, "status": "OK"},
... // 10개 역
]
},
... // 6명
]
}
구현 코드
public MidpointRecommendationResponse calculateMidpoint(Long locationPollId) {
// 1. 출발지 조회 (MySQL)
List<LocationVote> votes = locationVoteRepository
.findByLocationPoll_LocationPollId(locationPollId);
// 2. PostGIS 무게중심 계산 (다음 섹션)
CenterPointDto centerPoint = calculateCentroid(votes);
// 3. PostGIS 근처 역 검색 (다음 섹션)
List<Station> candidateStations = stationRepository
.findNearbyStations(centerPoint.latitude(), centerPoint.longitude(), 5000, 10);
// 4. 배치 좌표 생성
List<Coordinate> origins = votes.stream()
.map(v -> new Coordinate(v.getDepartureLat(), v.getDepartureLng()))
.toList();
List<Coordinate> destinations = candidateStations.stream()
.map(s -> new Coordinate(s.getLatitude(), s.getLongitude()))
.toList();
// 5. Google API 배치 호출 (2회)
// - Transit: 대중교통 경로 (6명 × 10역 = 60개)
// - Driving: 자가용 경로 (6명 × 10역 = 60개)
GoogleDistanceMatrixResponse transitResponse =
googleClient.calculateDistanceMatrix(origins, destinations, "transit");
GoogleDistanceMatrixResponse drivingResponse =
googleClient.calculateDistanceMatrix(origins, destinations, "driving");
// 6. 행렬 응답 파싱 및 평가
return evaluateAndRank(votes, candidateStations, transitResponse, drivingResponse);
}
핵심 차이
- CompletableFuture: 없음
- Semaphore: 없음
- 재시도 로직: 없음 (Google API는 안정적)
- 코드 라인 수: 300+ → 150 lines (50% 감소)
행렬 응답 파싱
private Element getElement(
GoogleDistanceMatrixResponse response,
int participantIndex, // 0~5 (6명)
int stationIndex // 0~9 (10개 역)
) {
return response.rows()
.get(participantIndex)
.elements()
.get(stationIndex);
}
// 사용 예시
for (int stationIdx = 0; stationIdx < stations.size(); stationIdx++) {
for (int participantIdx = 0; participantIdx < participants.size(); participantIdx++) {
Element transitElement = getElement(transitResponse, participantIdx, stationIdx);
int transitDuration = (transitElement != null && "OK".equals(transitElement.status()))
? transitElement.duration().value() / 60 // 초 → 분
: 999; // 실패 시 페널티
// RouteDto 생성...
}
}
장점
- 2차원 인덱싱으로 모든 경로에 O(1) 접근
- 실패한 경로는 999분으로 처리 → 순위 자동 하락
- 단순하고 명확한 로
4. 근본 해결 2: PostGIS 공간 쿼리
아키텍처 선택 과정: GeoTools vs PostGIS
지하철역 검색을 위한 공간 데이터 처리 방법을 선택할 때 크게 2가지 옵션을 고려했습니다
옵션 1: 자바 라이브러리 (GeoTools) + MySQL

장점
- MySQL 하나로 통합 관리
- 기존 DB 활용 방안
단점
- 참여자 좌표 수집 (무게중심 계산 복잡)
- 무계층성 계산 (정확도 낮음)
- 거리 역 DB에서 유클리디안 거리 기준 최인접 역 검색 (부정확)
GeoTools의 한계
- 참여자 좌표 수집이 복잡
- 무게중심 계산에 구면 좌표 변환이 복잡함
- 자체 역 DB에서 최인접 검색 시 유클리디안 거리 사용 (지구 곡률 미반영)
옵션 2: PostgreSQL + PostGIS (최종 선택)
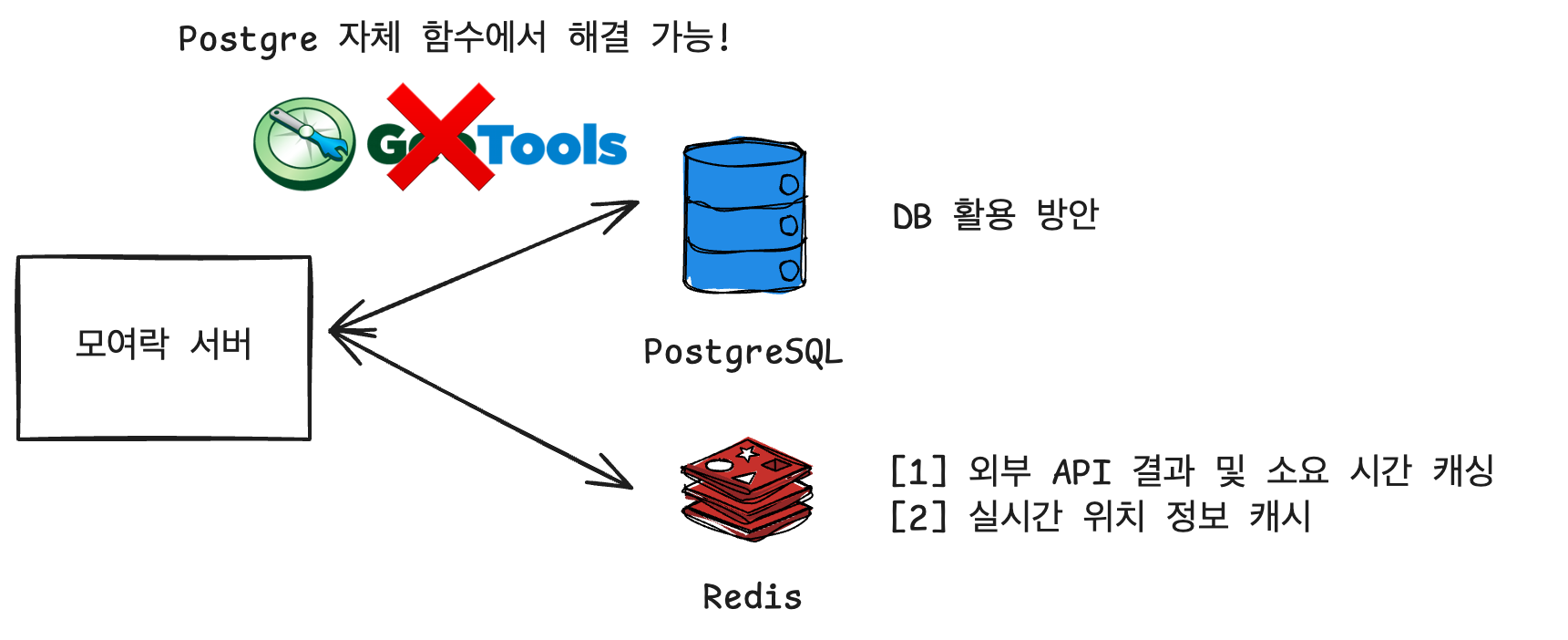
장점
- PostGIS 공간 데이터베이스로 무게중심 지오코딩 및 자하 조회 가능
- 비즈니스 로직형 지오코딩 및 역 검색
- GIST Index로 빠른 공간 쿼리 (< 10ms)
- 구면 거리 계산 (정확도 높음)
- 자체 역 DB 활용 방안 (외부 API 의존도 ↓)
단점
- DB 하나 더 관리 (인프라 복잡도 ↑)
- 듀얼 DB 설정 필요
결정적 이유
"공간 데이터는 공간 데이터베이스로 처리하자"
PostGIS는 이미 검증된 공간 데이터 처리 도구이고, GeoTools로 직접 구현하면
- 구면 좌표 변환 로직 직접 작성
- 인덱싱 최적화 직접 구현
- 정확도 검증 필요
트레이드오프
- 인프라 복잡도 ↑ (MySQL + PostgreSQL)
- 개발 생산성 ↑ (검증된 도구 활용)
- 성능 ↑ (GIST Index)
- 정확도 ↑ (구면 거리 계산)
→ 복잡도보다 정확도와 성능을 우선시
Kakao API → PostGIS 전환
Before: Kakao Local API
// Kakao API 호출 (300ms)
KakaoSearchResponse response = kakaoClient.searchSubwayStations(
centerPoint.latitude(),
centerPoint.longitude(),
5000 // 5km 반경
);
문제점
- 외부 API 의존 (네트워크 지연)
- 응답 시간 300ms
- Rate Limit 존재
After: PostGIS 공간 쿼리
-- PostGIS 반경 검색 (<10ms)
SELECT s.*
FROM stations s
WHERE ST_DWithin(
s.geom::geography,
ST_SetSRID(ST_MakePoint(:lng, :lat), 4326)::geography,
5000 -- 5km
)
ORDER BY ST_Distance(
s.geom::geography,
ST_SetSRID(ST_MakePoint(:lng, :lat), 4326)::geography
) ASC
LIMIT 10;
효과
- 응답 시간: 300ms → 10ms (97% 개선)
- 외부 API 의존도 감소
- 정확도 향상 (구면 거리 계산)
PostGIS 인프라 구성
듀얼 DB 아키텍처
MySQL (Primary - 3306) PostgreSQL (Secondary - 5432)
├─ Meeting ├─ Station (700+ 지하철역)
├─ Participant ├─ GIST Index (공간 인덱스)
├─ LocationVote └─ PostGIS Extension
└─ ScheduleVote
역할 분담
- MySQL: 비즈니스 도메인 (CRUD, 트랜잭션)
- PostgreSQL/PostGIS: 공간 연산 (반경 검색, 거리 계산)
PostGIS 테이블 구조
CREATE EXTENSION IF NOT EXISTS postgis;
CREATE TABLE stations (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
line VARCHAR(50),
geom GEOMETRY(POINT, 4326) NOT NULL -- WGS84 좌표계
);
-- GIST 공간 인덱스 (핵심!)
CREATE INDEX idx_stations_geom ON stations USING GIST(geom);
-- 데이터 삽입 (1~9호선, 신분당선, 경의중앙선 등 700개 역)
INSERT INTO stations (name, line, geom) VALUES
('소요산', '1호선', ST_SetSRID(ST_MakePoint(127.0611, 37.9481), 4326)),
('동두천', '1호선', ST_SetSRID(ST_MakePoint(127.0607, 37.9036), 4326)),
...
GIST Index
- Generalized Search Tree: 공간 인덱스
- ST_DWithin 쿼리를 O(log N)으로 최적화
- 700개 역 중 5km 반경 검색 < 10ms
무게중심 계산도 PostGIS로
Before: 애플리케이션 레벨 (산술 평균)
double avgLat = participants.stream()
.mapToDouble(ParticipantInfo::latitude)
.average()
.orElse(0.0);
double avgLng = participants.stream()
.mapToDouble(ParticipantInfo::longitude)
.average()
.orElse(0.0);
문제: 지구는 구형이므로 산술 평균은 부정확
After: PostGIS ST_Centroid (3D 좌표 변환)
SELECT ST_Y(centroid) AS lat, ST_X(centroid) AS lng
FROM (
SELECT ST_Centroid(ST_Collect(geom)) AS centroid
FROM unnest(CAST(:wktPoints AS geometry[])) AS geom
) sub
WKT 포맷 생성
String[] wktPoints = votes.stream()
.map(v -> "ST_SetSRID(ST_MakePoint(" +
v.getDepartureLng().doubleValue() + ", " +
v.getDepartureLat().doubleValue() + "), 4326)")
.toArray(String[]::new);
Object[] result = stationRepository.calculateCentroid(wktPoints);
double centerLat = (double) result[0];
double centerLng = (double) result[1];
효과
- 구면 기하학적 무게중심 (정확도 향상)
- 소요 시간: ~15ms
5. 성능 개선 결과
전체 응답 시간 분석 (참여자 3명)
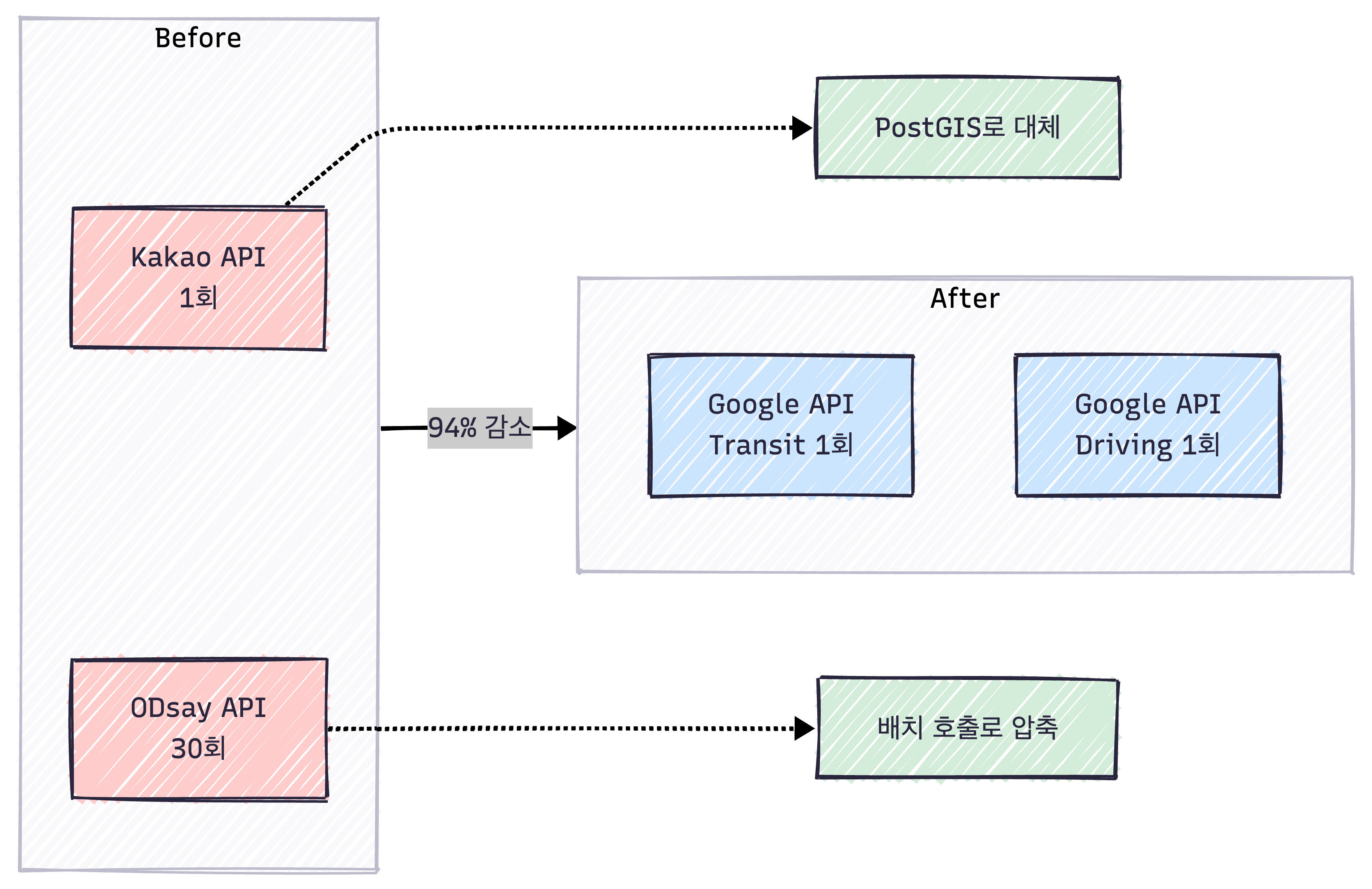
Before: 병렬 호출 + 외부 API 의존 2개 (ODsay, Kakao)
After: PostgreSQL + PostGIS + Google 배치 API

API 호출 횟수 비교
| 항목 | Before | After | 개선율 |
| 지하철역 검색 | Kakao API 1회 | PostGIS 쿼리 | 외부 API 제거 |
| 경로 탐색 | ODsay API 30회 (대중교통만) | Google API 2회 (대중교통+자가용) | ↓ 93% |
| 총 외부 API 호출 | 31회 | 2회 | ↓ 94% |
2회 배치 호출의 구성
- 1회: Transit 모드 (6명 × 10역 = 60개 대중교통 경로)
- 1회: Driving 모드 (6명 × 10역 = 60개 자가용 경로)
- 총 120개 경로 정보를 2회 호출로 조회
비용 분석
Google API 무료 쿼터
- 월 40,000 elements 무료
- 1회 요청 = 60 elements (6명 × 10역 × 1모드)
- Transit + Driving = 120 elements/요청
- 월 사용 가능 횟수: 약 333회 (40,000 / 120)
예상 사용량:
- 초기 MVP: 하루 10회 × 30일 = 300회/월 → 무료 쿼터 내
- 성장 후: 비용 대비 UX 개선 효과 충분
사용자 경험 개선
| 시나리오 | Before | After | 체감 |
| 참여자 6명 | 12초 대기 😫 | 0.9초 대기 😊 | 즉각 반응 |
| 참여자 10명 | 20초 대기 💀 | 1.2초 대기 😊 | 즉각 반응 |
| 외부 API 장애 | 전체 실패 | PostGIS로 부분 동작 | 안정성↑ |
6. 배운 점: 서비스 개발 관점
6.1. "복잡한 최적화"의 함정
잘못된 접근
문제: API가 느리다
해결: 병렬 처리하자!
새 문제: Rate Limit 걸린다
해결: Semaphore로 제한하자!
새 문제: 429 에러 발생한다
해결: 재시도 로직 추가!
새 문제: 코드가 너무 복잡하다...
함정: 근본 원인(배치 호출 미지원)을 해결하지 않고 증상만 치료
올바른 접근
근본 원인: ODsay가 배치 호출을 지원하지 않는다
근본 해결: 배치 호출을 지원하는 Google API로 전환
부가 효과: 복잡한 동시성 제어 로직 모두 제거
"올바른 도구를 선택"하면 복잡한 로직이 필요 없어진다
6.2. 외부 API 선택 기준 (서비스 개발자 관점)
초기 단계에서 확인해야 할 것
1. 배치 호출 지원 여부
- N×M 문제가 예상되면 필수
- 지원하지 않으면 성능 최적화에 한계 명확
2. Rate Limit 합리성
- 초당 5회 vs 초당 100회 = 20배 차이
- 엄격한 제한 = 복잡한 동시성 제어 필요
3. 비용 대비 가치
- 무료 API가 항상 좋은 것은 아님
- 개발 시간 + 유지보수 비용도 고려
- "개발자 3일 투입 vs API 비용 월 5만원" → API 선택이 합리적
4. 확장성
- 참여자/데이터가 늘어날 때 선형 확장 가능한지
- ODsay: 참여자 10명 → 20초 (확장 불가)
- Google: 참여자 10명 → 1.2초 (선형 확장)
6.3. 비교: Before/After
아키텍처
Before: ODsay + 순차 호출

After: Google + PostGIS

API 호출 패턴 비교
Before: ODsay 순차 호출 (30회)

After: Google 배치 호출 (2회)

성능 개선 타임라인
7. 마무리
"문제를 더 복잡하게 해결하는 것보다
문제의 근본 원인을 올바르게 정의하고
적합한 도구를 선택하는 것이 더 중요하다"
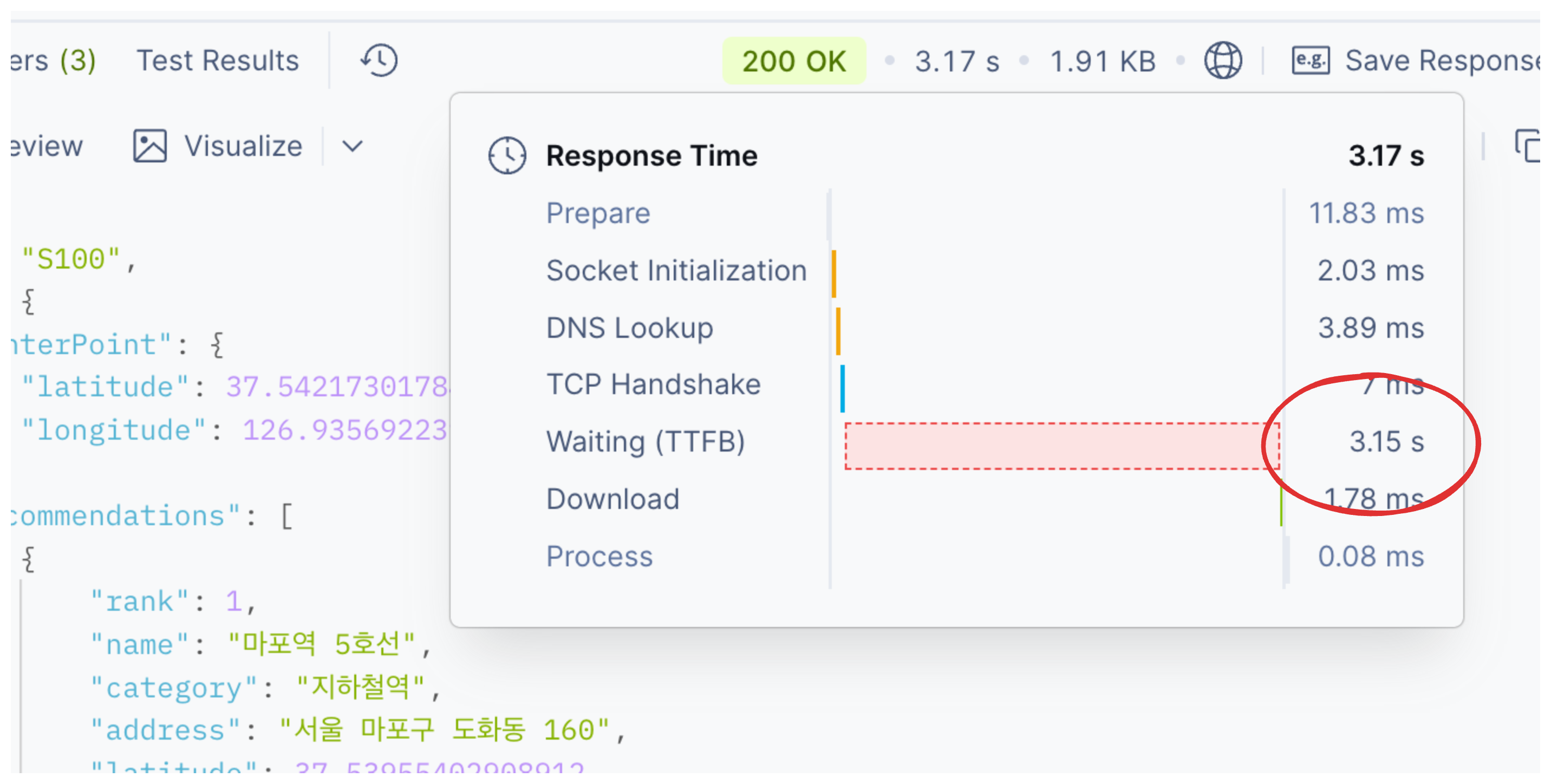
3.49s초였던 API가 0.925ms로 73% 개선된 것도 의미 있지만 더 중요한 것은 300줄의 복잡한 동시성 제어 코드를 150줄의 단순한 배치 호출 로직으로 대체하며 "서비스 개발에서 진짜 중요한 것이 무엇인지" 배운 것입니다.
앞으로도 "올바른 문제"를 찾고 "올바른 도구"를 선택하는 엔지니어가 되고 싶습니다.